📂 文章分类:How To
摘要: 本文详解 Agentic RAG 的核心原理与工作流程。通过对比传统技术,阐述其基于自主推理的动态检索优势。结合 Dify 平台特性、典型应用场景及潜在局限,为开发者提供构建智能知识系统的实践指南。
Agentic RAG:通过自主推理实现更高效的动态检索
检索增强生成(RAG)是一项强大的技术架构,它将大语言模型(LLM)与外部知识库深度融合。该技术使 LLM 能够主动召回相关文档,并将其作为上下文参考,从而大幅提升回答用户问题的准确性。
在传统的 RAG 流程中,系统会先将用户查询转换为向量表示,随后在知识图谱或数据库中执行相似度搜索。接着,系统将排名前 k 的召回结果直接发送给 LLM 进行答案生成。这种方法虽然能有效抑制模型幻觉,让回复严格锚定事实数据,但也存在明显局限:检索过程是“一次性”的,缺乏推理能力;且当初始搜索结果不佳时,系统无法动态调整策略。
什么是 Agentic RAG?
Agentic RAG 通过将检索流程嵌入智能推理循环,有效突破了上述瓶颈。它不再将检索视为固定的预处理步骤,而是将其深度融入 Agent(智能体)的决策链路中。由 LLM 驱动的 Agent 会深入解析用户查询、规划执行路径、动态选择工具与数据源、评估召回内容质量,并在必要时自动重试或切换策略。
这种动态检索机制使 RAG 转变为灵活自适应框架,能更高效地处理模糊或多步骤任务。尤其在需要跨多源推理的场景中,Agentic RAG 能在生成答案前充分验证初始检索结果的有效性。
Traditional RAG vs Agentic RAG
| 对比维度 | Traditional RAG | Agentic RAG |
|---|---|---|
| 检索逻辑 | 一次性(One-shot) | 多步迭代,循环优化 |
| 工具灵活性 | 固定检索器 | 支持多种工具动态切换 |
| 推理能力 | 无 | 具备自主推理 |
| 查询优化 | 不支持 | 支持自动改写与细化 |
| 结果评估 | 无(直接生成) | 有反馈循环,持续验证 |
| 答案可靠性 | 依赖初始搜索结果 | 通过迭代显著提升 |
Agentic RAG 是如何工作的?
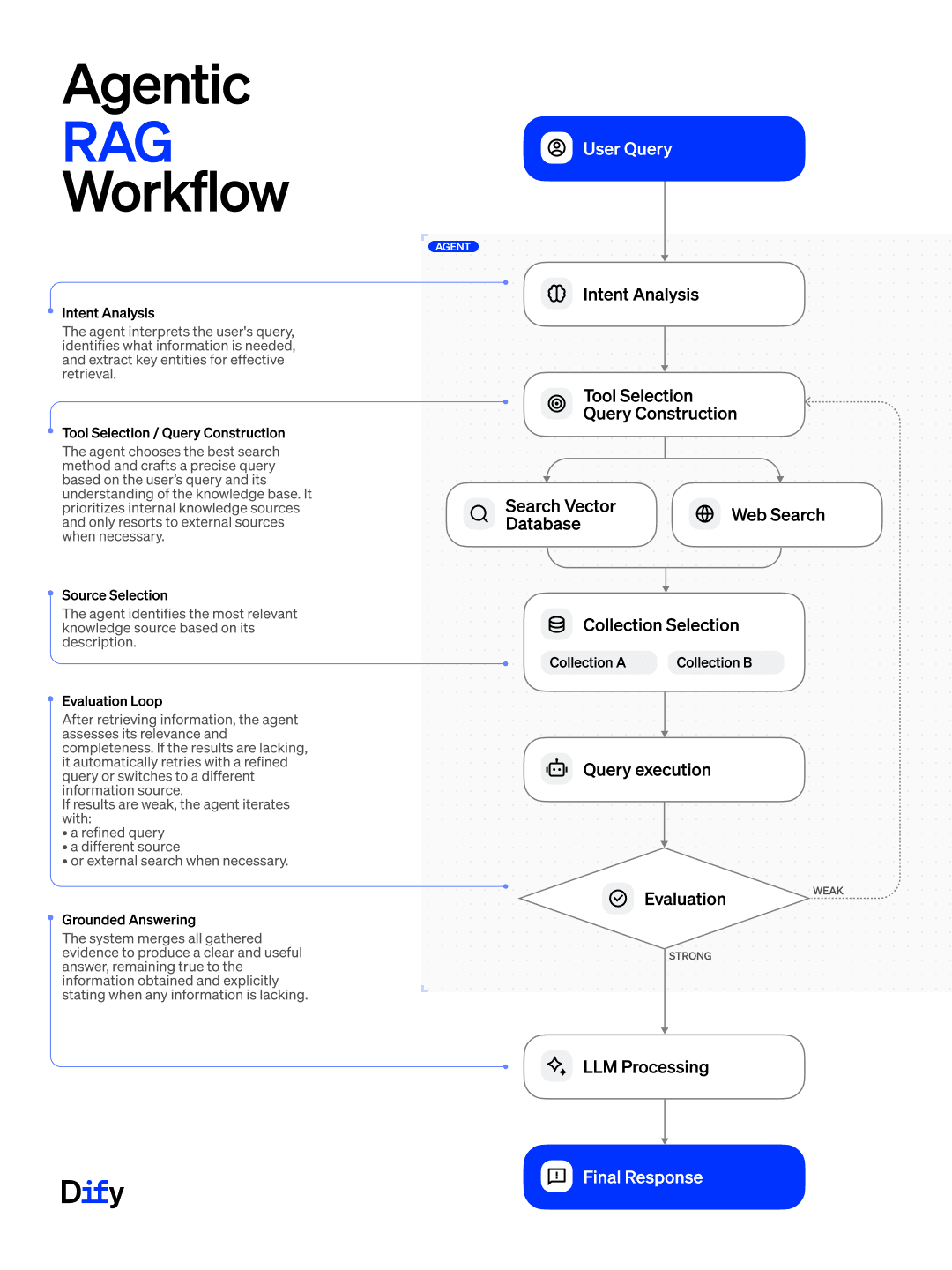
Agentic RAG 将推理能力引入检索的每个环节。典型工作流程包含以下步骤:
- 意图分析(Intent Analysis):Agent 解析用户查询,明确所需信息类型。提取关键概念与实体后,推断搜索目标。
- 工具选择与查询构建(Tool Selection & Query Construction):根据查询特征,Agent 自动匹配最佳检索方式(如向量检索、混合检索、关键词或网页搜索)。随后生成适配该工具的优化查询语句。
- 数据源/集合路由(Source / Collection Selection):若存在多个知识库,Agent 会基于元数据、数据结构或历史经验判断最相关的集合,并将请求精准路由至对应目标。
- 执行检索(Query Execution):调用选定的工具与数据集召回候选文档。系统对结果进行排序后,将信息回传至 Agent。
- 评估循环(Evaluation Loop):Agent 严格审查召回内容的质量。若发现覆盖不全或相关性低,会自动改写查询、切换检索工具,甚至触发备用方案(如转为网页搜索)。该循环将持续运行,直至满足质量要求或达到最大迭代次数上限。
- 基于证据的答案生成(Grounded Answer Generation):仅在确认依据充分后,系统才会进入最终答案生成阶段。确保输出内容严格锚定于已验证的相关资料。
该方法彻底改变了盲目检索的模式,使整个过程转变为受推理与评估引导的自适应步骤。
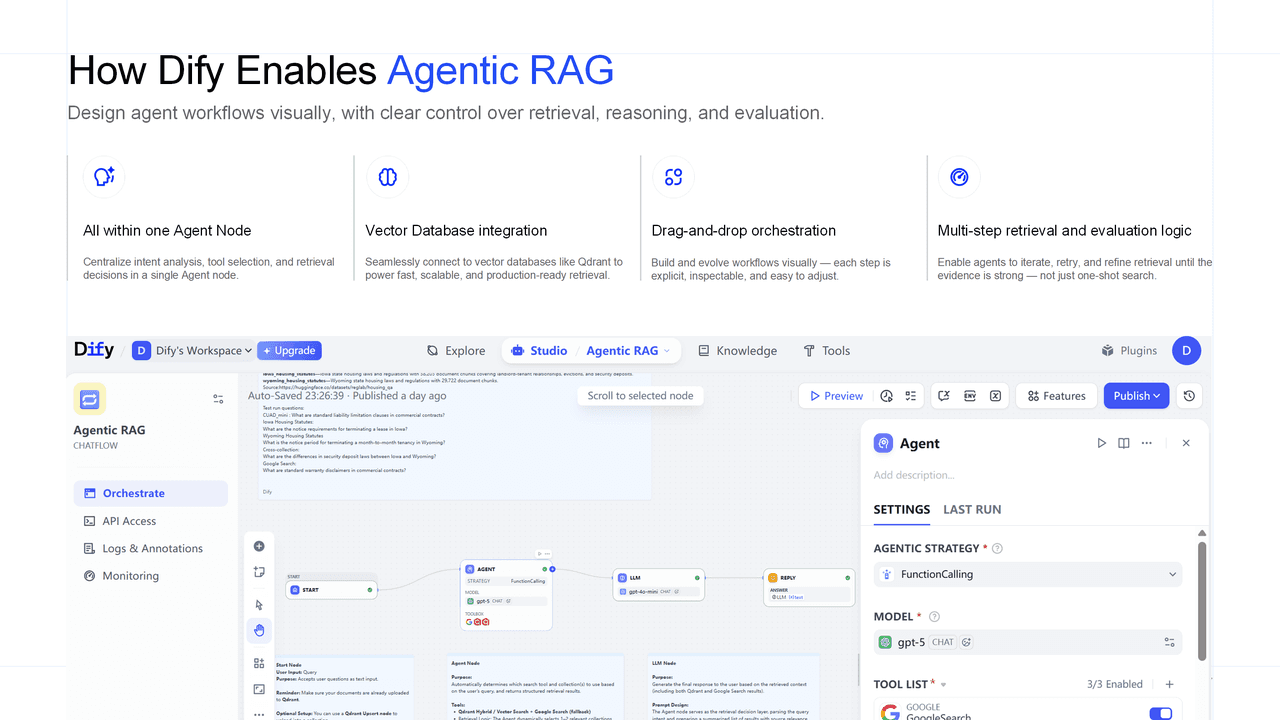
Dify 如何赋能 Agentic RAG?
Dify 提供了一套落地 Agentic RAG 的实用框架,核心能力包括:
- Agent 节点:作为集中式决策引擎,整合意图分析、工具编排、数据源路由与重试逻辑。完整封装 Agent 行为。
- 可视化工作流构建器(Drag-and-Drop Workflow Builder):支持通过拖拽方式创建复杂的多步流程。每个推理或执行动作均可独立配置为节点。
- 原生工具集成:内置 Qdrant(向量与混合检索)、Google Search 及自定义 API,开箱即用。
- 迭代策略支持:提供内置重试、细化查询与降级 fallback 机制。开发者可通过 Function Calling 或 ReAct 等模式灵活定义行为逻辑。
Dify 将全部检索逻辑收敛至单一节点中,使 Agentic RAG 工作流具备高透明度、易复用且便于持续演进的特性。
典型应用场景
Agentic RAG 在以下场景中表现尤为出色:查询模糊、涉及多步骤推理,或初始上下文信息不足;检索范围需跨越不同格式、领域或多数据源;系统必须具备自主决策能力与异常降级机制。代表性案例包括:
- 企业知识助手:将复杂员工咨询精准路由至 HR 文档、内部 Wiki 及产品政策库。例如:“加州远程办公的员工能否报销联合办公空间费用?”
- 法律或科研助理:从结构化数据集、学术论文及监管指南中交叉检索信息,辅助事实核查或多法域对比分析。
- 开发者 Copilot:查询内部代码仓库、技术文档与构建/测试报告;可选配调用 Linter 或静态分析工具进行深度验证。
- AI 工作流助手:将知识检索与摘要生成、格式排版或邮件发送等操作串联,广泛应用于运营与团队协作流程。
- 智能客服 Agent:跨 CRM 系统、产品手册与支持工单库进行搜索;若信息不足可自动追问或升级转人工处理。
这些场景均高度依赖 Agentic RAG 在多重知识边界内自适应调整与自我修正的能力。
需关注的局限性
- 响应延迟(Latency):多步推理与自动重试机制会自然增加整体耗时。
- LLM 推理质量依赖:若提示词设计不佳,Agent 可能做出次优决策甚至陷入无效循环。
- 成本上升(Higher Cost):迭代查询与多次工具调用将显著消耗 Token 并推高算力开销。
- 运维复杂度增加:需精心设计 Prompt、设置重试上限及降级规则,以防资源浪费或工具滥用。
Agentic RAG 在控制精度与系统可靠性方面引入了新挑战。实际落地时务必配套完善的护栏机制(Guardrails)、全链路日志追踪与严谨的策略设计。
总结
Agentic RAG 标志着知识检索从“静态匹配”向“动态决策驱动”的范式转变。通过将检索深度融入推理闭环,系统得以实现自适应调整、多轮迭代与结果验证,从而显著提升最终答案的质量。借助 Dify 等低代码平台,团队能够以可视化、模块化的方式快速构建此类应用。在追求高可信度、高精度或强上下文灵活性的业务中,Agentic RAG 工作流将发挥关键作用。随着 LLM 从被动应答者向自主智能体演进,Agentic RAG 必将成为下一代 AI 架构的核心模式之一。
如需了解 Agentic RAG 的深入解析及 Dify 落地实操,欢迎观看本次技术研讨会:
[查看回放/详情](注:原文为 On this page)
原文图片