在 NVIDIA DGX Spark 上使用 Dify 部署私有 AI Agent
摘要:本文介绍了如何利用 NVIDIA DGX Spark 桌面级 AI 超级计算机与 Dify AI 应用开发平台结合,构建端到端的本地化私有 AI 解决方案。通过整合硬件算力、推理引擎与应用编排层,企业可在确保数据隐私合规的前提下,零代码快速搭建智能客服、研发助手等垂直领域 AI Agent,实现从数据处理到模型推理的全链路内网部署。
我们最近测试了 NVIDIA DGX Spark™。这款体积类似 Mac mini 的桌面级 AI 超级计算机,将企业级的 GPU 性能浓缩在一个紧凑的外壳中。结合 Dify AI 应用开发平台,它为企业提供了一种端到端的私有化 AI 部署方案。
通过组合使用 Dify 和 DGX Spark,组织可以将 AI Agent 完全运行在本地环境中。从数据摄入、模型推理到应用交付整个流程都保留在你的局域网内,从而确保数据安全与合规性。


从硬件到基础设施:全集成技术栈
Dify 与 DGX Spark 的组合提供了一套从底层硬件到上层基础设施的完整集成方案:
1. 硬件层 (Hardware)
DGX Spark 集成了完整的 NVIDIA AI 平台,包括 GPU、CPU、网络架构、CUDA® 库以及 NVIDIA AI 软件堆栈。它由 NVIDIA GB10 Grace Blackwell Superchip 驱动,拥有 128GB 统一内存和高达 1 petaflop (PFLOP) 的 FP4 AI 算力。
DGX Spark 支持本地推理主流开源模型(如 Llama 3、Qwen 2.5、DeepSeek V3)以及 NVIDIA 自有模型(Nemotron, NVIDIA NIM)。
2. 平台层 (Platform)
在此基础上,Dify 平台提供了以下核心能力:
* 可视化工作流编排:通过拖拽方式构建复杂逻辑。
* 集成知识库管道:无缝接入 RAG 技术。
* 统一的多模型管理:轻松切换和管理不同的大语言模型。
借助这套技术栈,企业可以在本地环境中零代码构建 AI Agent,同时确保数据输入、模型推理和应用输出的全生命周期都在内网中完成。

NVIDIA DGX Spark:桌面级 AI 算力
DGX Spark 于 10 月 15 日发布,它消除了传统上对云基础设施或大型数据中心服务器的依赖。它为 AI 开发者、中小企业 (SMBs) 和研究机构提供了一种易于获取的本地化计算选项。
关键规格:
* 芯片:GB10 Grace Blackwell Superchip
* CPU:20核 Arm CPU
* GPU架构:Blackwell Architecture GPU
* 内存:128 GB 统一内存 (Unified Memory)
* 算力:高达 1 PFLOP FP4 AI 计算能力
* 模型支持(单设备):可运行参数规模达 200B 的模型
* 模型支持(双机互联):可运行参数规模达 405B 的模型
开发者可以直接在桌面上部署模型并构建应用,保持数据和计算的本地化。
使用 Dify 和 DGX Spark 构建私有 AI Agent
团队可以通过结合 Dify 的应用平台与 DGX Spark 的计算能力,快速构建私有化的 AI Agent。
架构概览
该架构由四层组成,形成了一个从硬件到业务应用的闭环:
-
硬件层 (Hardware Layer)
NVIDIA DGX Spark 提供本地 GPU 算力和统一内存,支持大规模模型的加载和高性能推理。 -
推理层 (Inference Layer)
- 部署主流开源模型(如 Llama 3, Qwen 2.5, DeepSeek V3)以及 NVIDIA 自有模型(Nemotron-4)。
- 通过 Ollama、vLLM 或 TensorRT-LLM 暴露推理 API。
-
应用层 (Application Layer)
Dify 平台提供可视化工作流编排、集成 RAG 知识库、多模型路由与管理,以及零代码 AI 应用开发能力。 -
业务层 (Business Layer)
- 企业级 AI Agent:支持智能客服、研发 Copilot(副驾驶)、数据分析助手及其他垂直领域的专用 AI Agent。
实施步骤
1. 环境准备
在 DGX Spark 上安装 Docker,并确保 Docker Engine正在运行。
2. 在 DGX Spark 上部署 Dify
完整指南请参考 官方 Dify 文档。
基本操作步骤如下:
git clone https://github.com/langgenius/Dify.git
cd Dify/docker
cp .env.example .env
docker compose up -d
容器运行后,访问 http://localhost/install 进行初始化设置。(如果在远程服务器上运行,请将 localhost 替换为服务器 IP)。
3. 部署本地模型与推理引擎
详细的模型部署说明请参考 官方 NVIDIA DGX Spark 文档。
我们将部署一个 TensorRT-LLM 环境,以便在本地 GPU 上服务大模型。
关键步骤:
-
初始化运行时 (Initialize Runtime)
验证 Docker 权限、GPU 驱动和容器运行时,确保 Spark 能识别到本地 GPU。 -
配置环境变量与缓存 (Configure Environment Variables and Caching)
设置 Hugging Face Token 和本地缓存目录,以避免重复下载模型文件。
# 创建 Hugging Face 缓存目录
mkdir -p $HOME/.cache/huggingface/
- 验证 TensorRT-LLM
使用 NVIDIA 容器镜像来验证环境是否正常工作。以下示例使用了Llama-3.1-8B-Instruct-FP4:
export MODEL_HANDLE="nvidia/Llama-3.1-8B-Instruct-FP4"
docker run \
-e MODEL_HANDLE=$MODEL_HANDLE \
-e HF_TOKEN=$HF_TOKEN \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
--rm -it --ulimit memlock=-1 --ulimit stack=67108864 \
--gpus=all --ipc=host --network host \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c ' hf download $MODEL_HANDLE && \
python examples/llm-api/quickstart_advanced.py \
--model_dir $MODEL_HANDLE \
--prompt "Paris is great because" \
--max_tokens 64 '
这将下载模型,初始化运行时,并运行一个测试提示词。
DGX Spark 支持的模型包括:
* Llama 3.1 FP4
* GPT-OSS 20B
* Qwen 2.5-VL 7B
启动本地推理服务 (Starting a Local Inference Service)
环境验证通过后,使用 trtllm-serve 启动持久化服务。以下以 Llama-3.1-8B-Instruct-FP4为例:
export MODEL_HANDLE="nvidia/Llama-3.1-8B-Instruct-FP4"
docker run --name trtllm_llm_server --rm -it --gpus all --ipc host --network host \
-e HF_TOKEN=$HF_TOKEN \
-e MODEL_HANDLE="$MODEL_HANDLE" \
-v $HOME/.cache/huggingface/:/root/.cache/huggingface/ \
nvcr.io/nvidia/tensorrt-llm/release:spark-single-gpu-dev \
bash -c ' hf download $MODEL_HANDLE && \
cat > /tmp/extra-llm-api-config.yml <<EOF print_iter_log: false kv_cache_config: dtype: "auto" free_gpu_memory_fraction: 0.9 cuda_graph_config: enable_padding: true disable_overlap_scheduler: true
EOF
trtllm-serve "$MODEL_HANDLE" \ --max_batch_size 64 \ --trust_remote_code \ --port 8355 \ --extra_llm_api_options /tmp/extra-llm-api-config.yml '
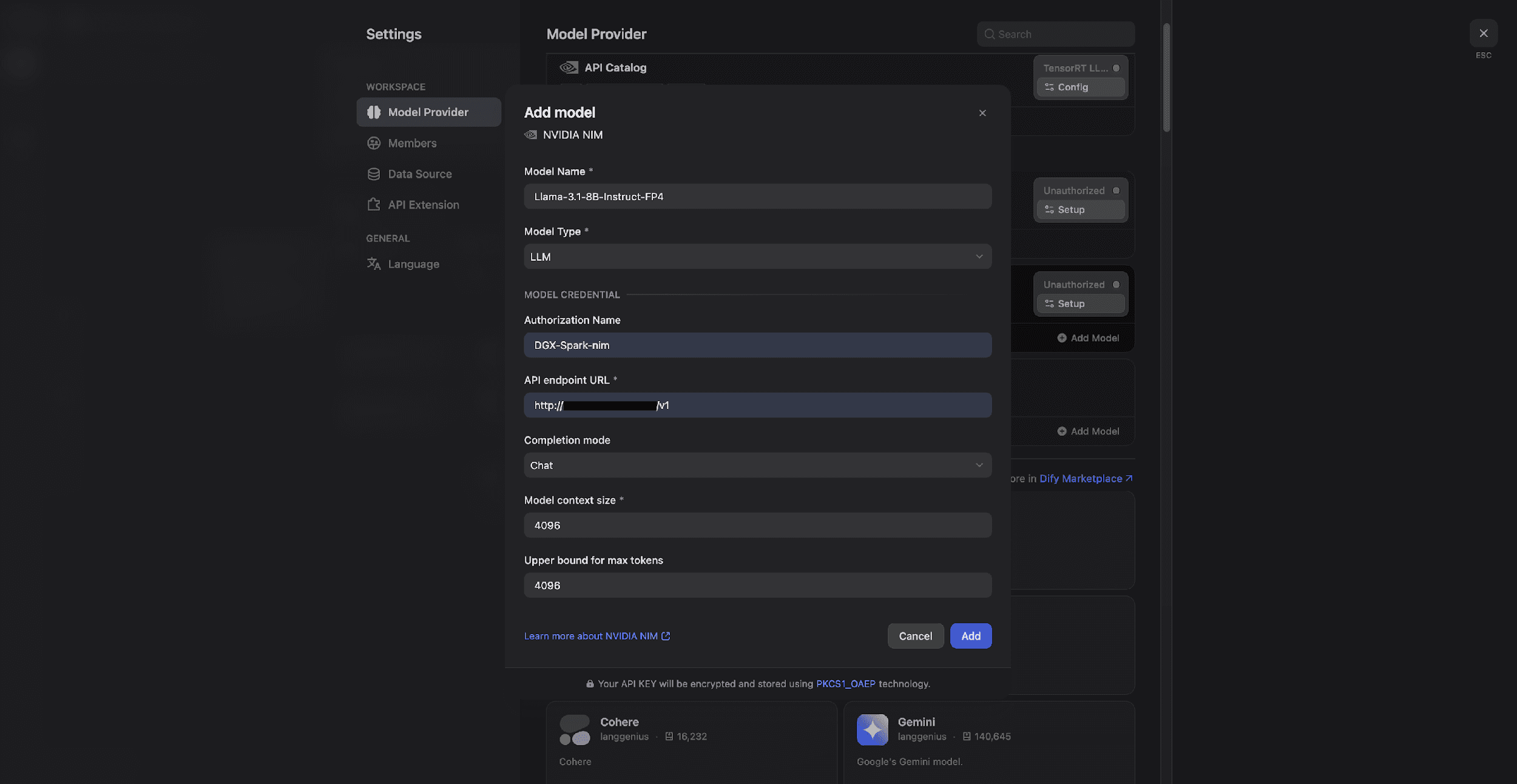
4. 将模型连接至 Dify
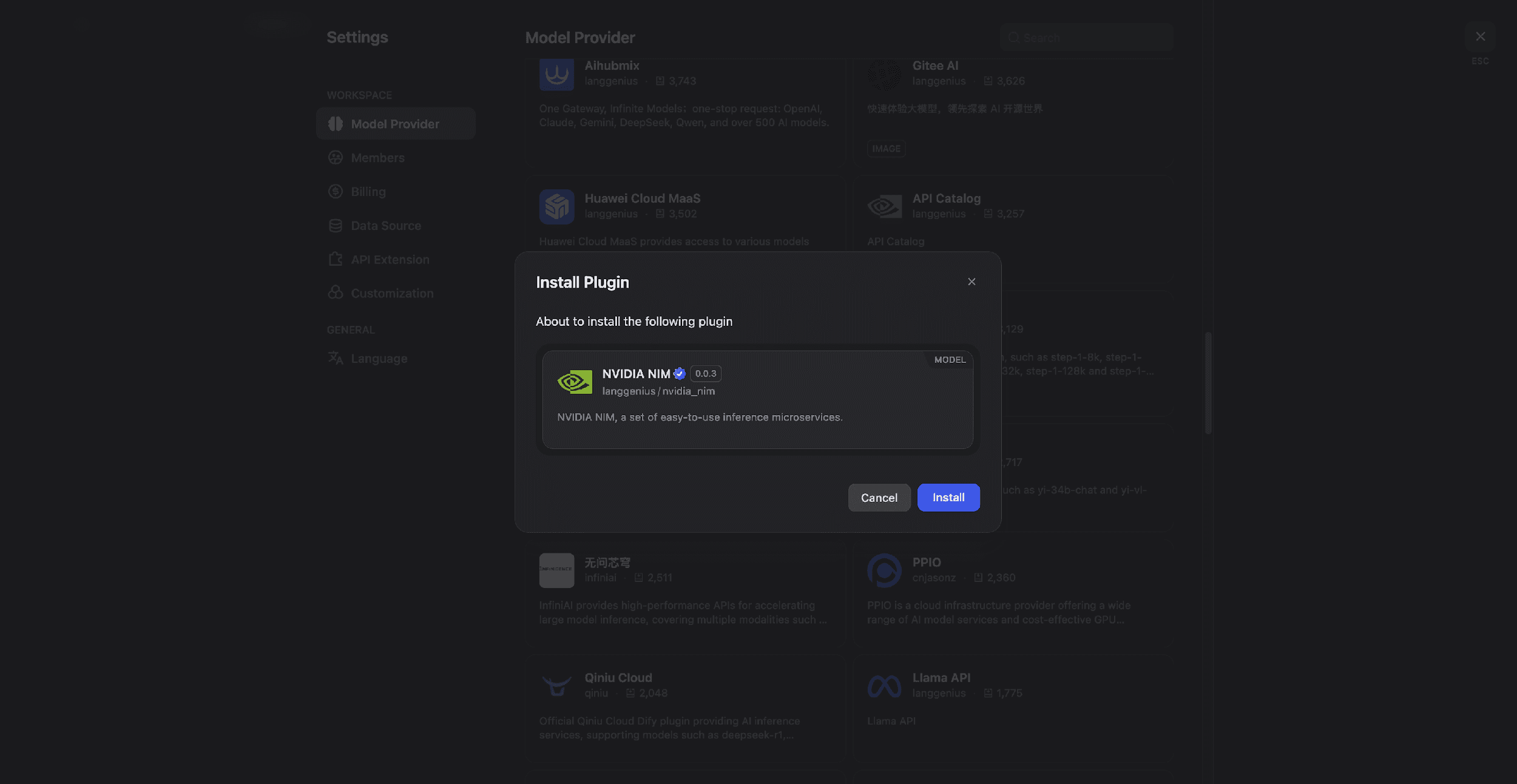
1) 进入 Dify 设置 (Settings) → 模型供应商 (Model Provider)。
2) 搜索并安装 NVIDIA NIM 插件。
3) 输入凭据:
* 模型名称:例如 Llama-3.1-8B-Instruct-FP4
* API URL:使用默认地址或从你的 .env文件中获取的地址。
5. 使用 Dify 构建 AI 应用
首先选择一种应用程序类型:
- Chatflow (对话流):专为多轮对话体验设计。
- Workflow (工作流):用于自动化复杂的业务流程。
- Agent:处理需要自主决策和工具调用的智能任务。
这三种模式均支持零代码开发,使团队能快速从想法过渡到生产就绪的应用程序。在前面的步骤中,我们已经在 DGX Spark 上部署并验证了本地推理服务。接下来,在 Dify 中选择合适的应用模板,快速搭建连接业务需求的示例应用。
示例:深度研究工作流 (Deep Research Workflow)
我们将使用 Template Marketplace(模板市场)创建一个 Deep Research 工作流。该模板预置了核心路径,涵盖 LLM 推理、搜索初始化、迭代搜索和分析总结等功能。根据用户的问题和研究深度的要求,它会自动执行完整的研究管道:解析 (Parse) → 搜索 (Search) → 迭代 (Iterate) → 推理 (Reason) → 报告生成 (Report Generation)。这使得该工作流非常适合技术选型、行业研究和复杂问题分析等专业场景。
在此工作流中,LLM 节点充当“大脑”。我们将此节点配置为在 DGX Spark 上运行 Llama-3.1-8B-Instruct,从而实现更深入的本地化分析能力。
![](https://framerusercontent.com/im