本文介绍如何将 Tavily 网络搜索 API 集成至 Dify 市场,作为数据源插件使用。通过 Dify 的知识流水线功能,用户可灵活编排 RAG 工作流,实时抓取网络数据并生成问答对,快速构建精准、上下文感知的 AI 应用。
Dify x Tavily:从实时网络数据构建知识流水线
今天,我们很高兴地宣布:专为 AI 应用、RAG 和智能体工作流设计的网络搜索 API——Tavily,现已作为数据源插件上线 Dify 市场。
几周前,我们推出了 Dify 知识流水线(Knowledge Pipeline)。这是用户编排 RAG 工作流的全新起点。从数据源上传解析,到文本分块与向量化,每个环节都支持灵活插拔。这种高灵活性让用户能为非结构化数据定制最优 RAG 方案,确保 LLM 的回复既准确又具备上下文感知能力。
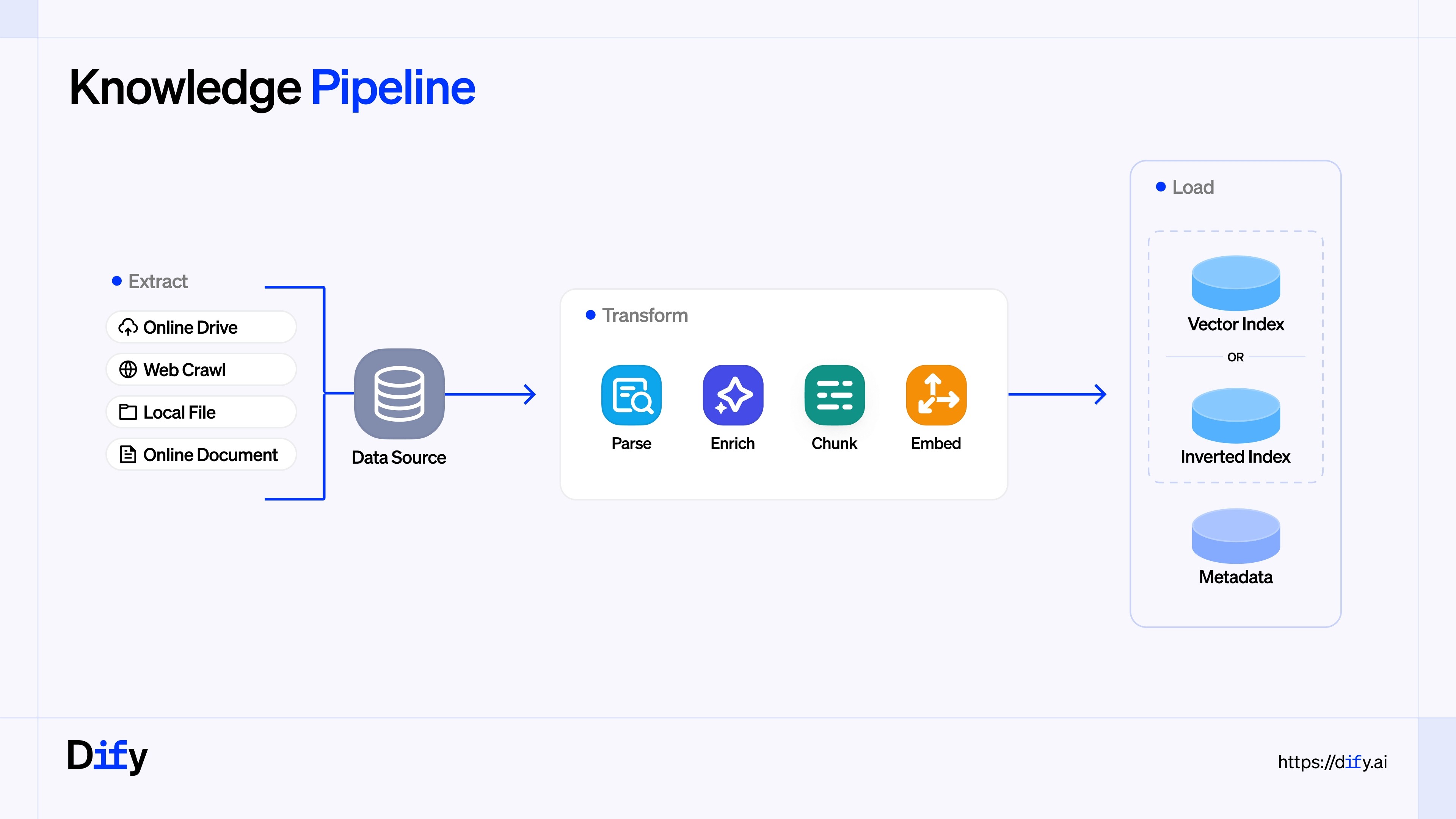
下文将为您详细拆解,如何将 Tavily 无缝融入您的知识流水线。
开始使用 Tavily
环境配置
- 从 Dify 市场安装 Tavily 插件。
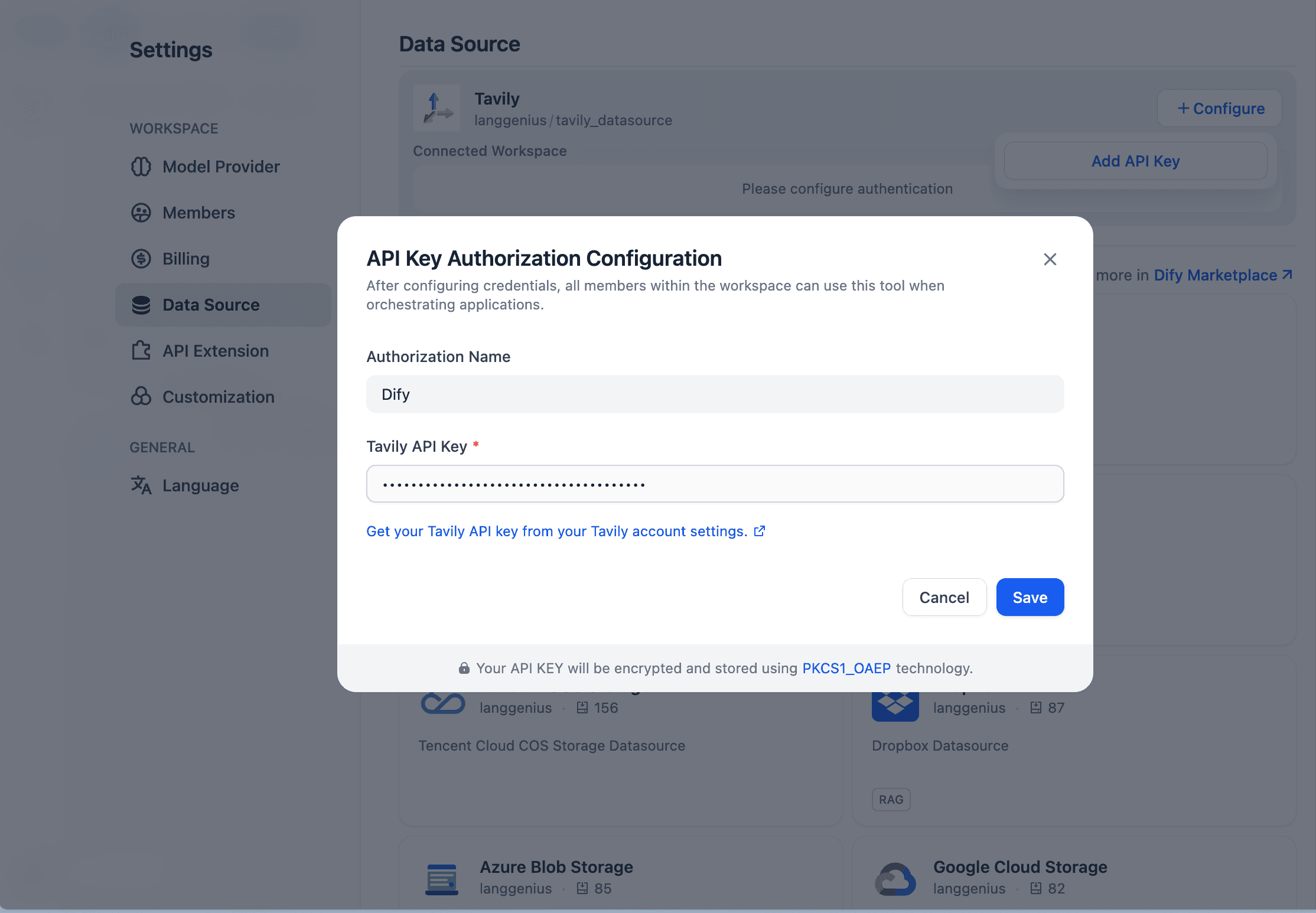
- 前往 Tavily 官网注册免费账号,获取 API Key。随后在 Dify 中完成配置:进入「设置」>「数据源」>「Tavily」,填入 Key 即可。
构建流水线
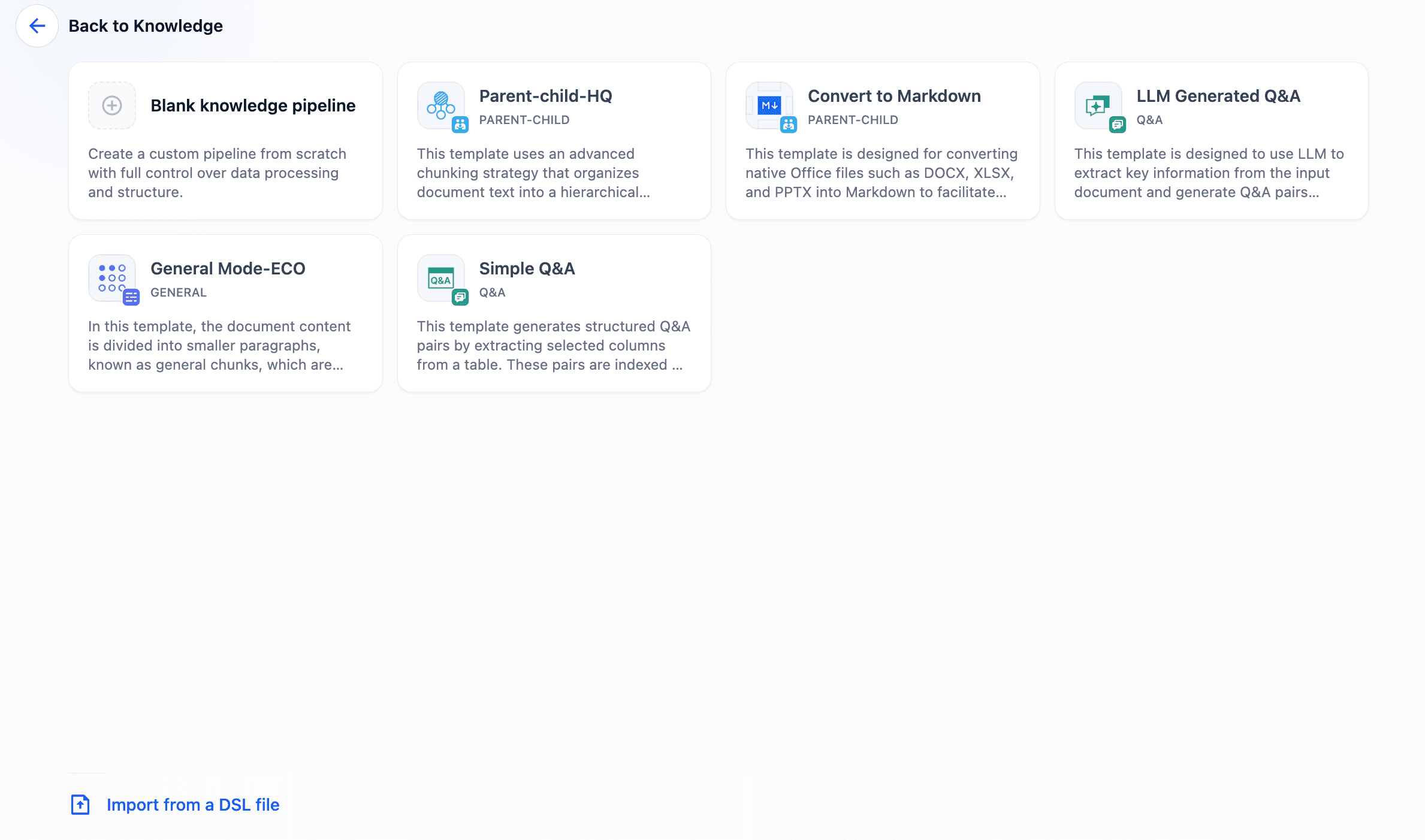
选择预设模板,或从零开始搭建。
我们已针对常见场景准备了多款模板:基础文档、长篇技术手册、复杂 PDF 以及结构化表格。您可以直接选用模板,按需微调后一键部署。
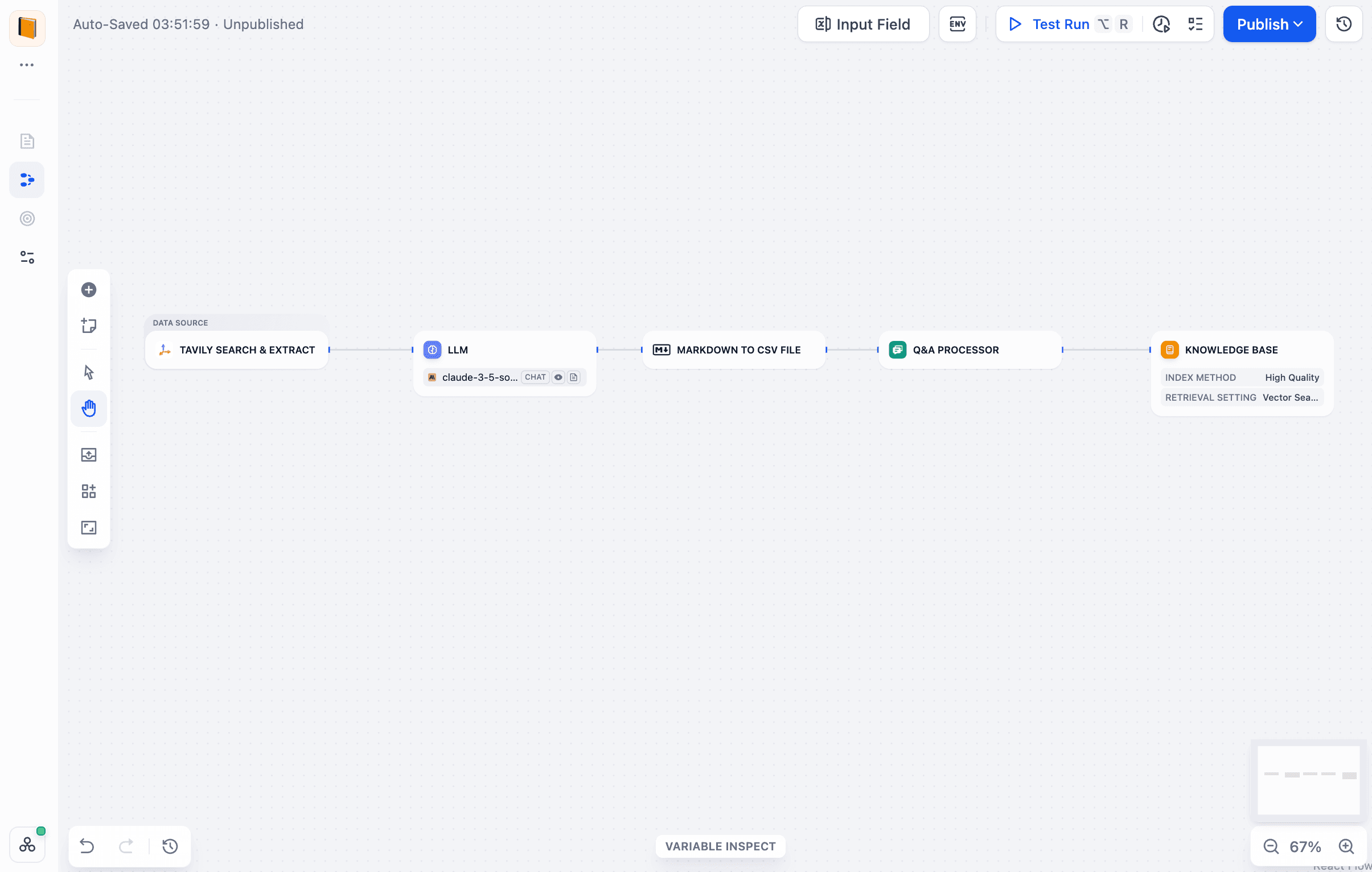
以下是一种典型用法:选用「LLM 生成问答对」模板,并将 Tavily 设为数据源。
该流水线会调用 LLM,从 Tavily 的网络抓取结果中提取关键信息,并自动生成问答对。处理后的数据将存入知识库,供后续按需检索。
使用建议
- 在设置中创建变量,用于接收搜索查询输入。
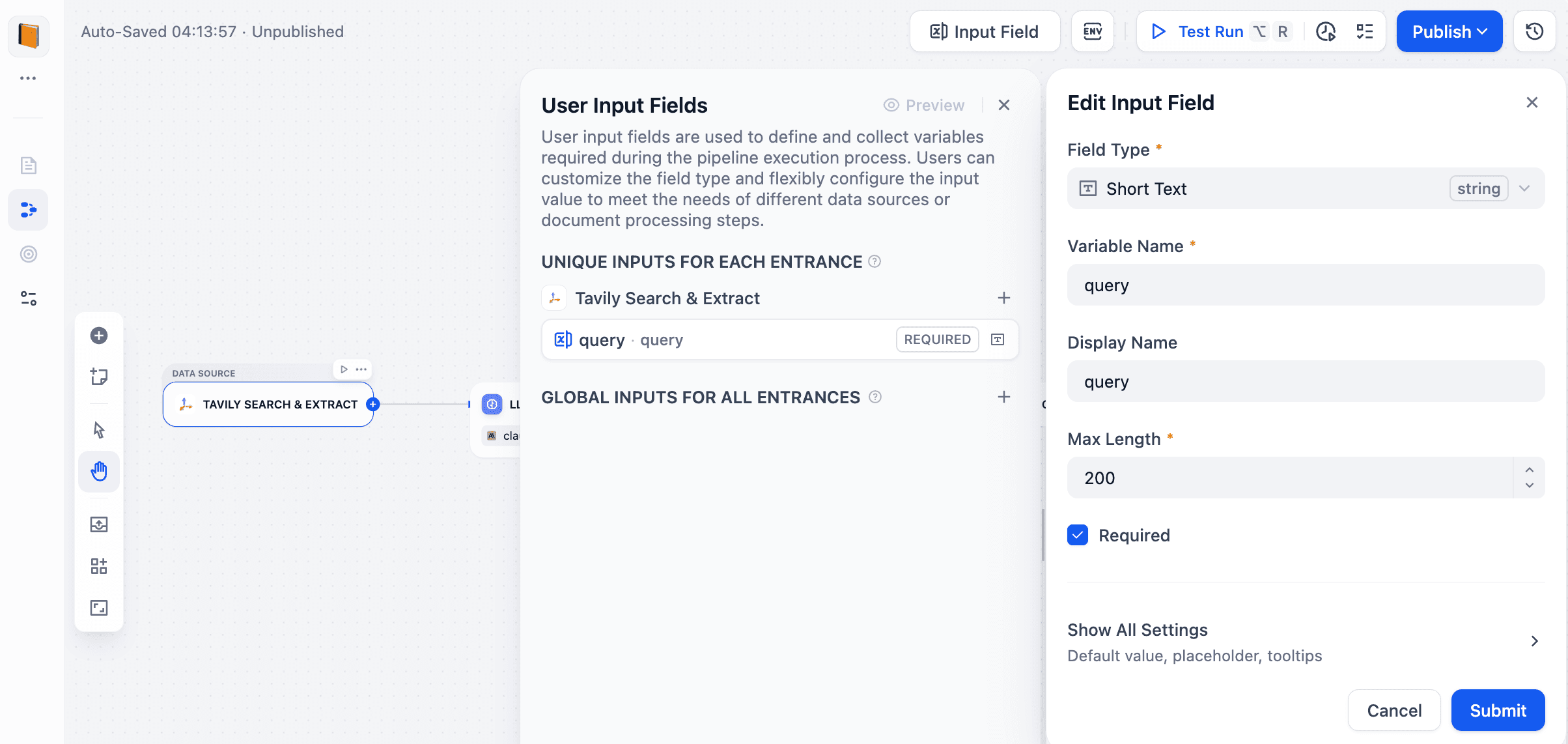
- 根据实际场景调整抓取参数(如搜索深度、最大结果数、主题过滤等)。
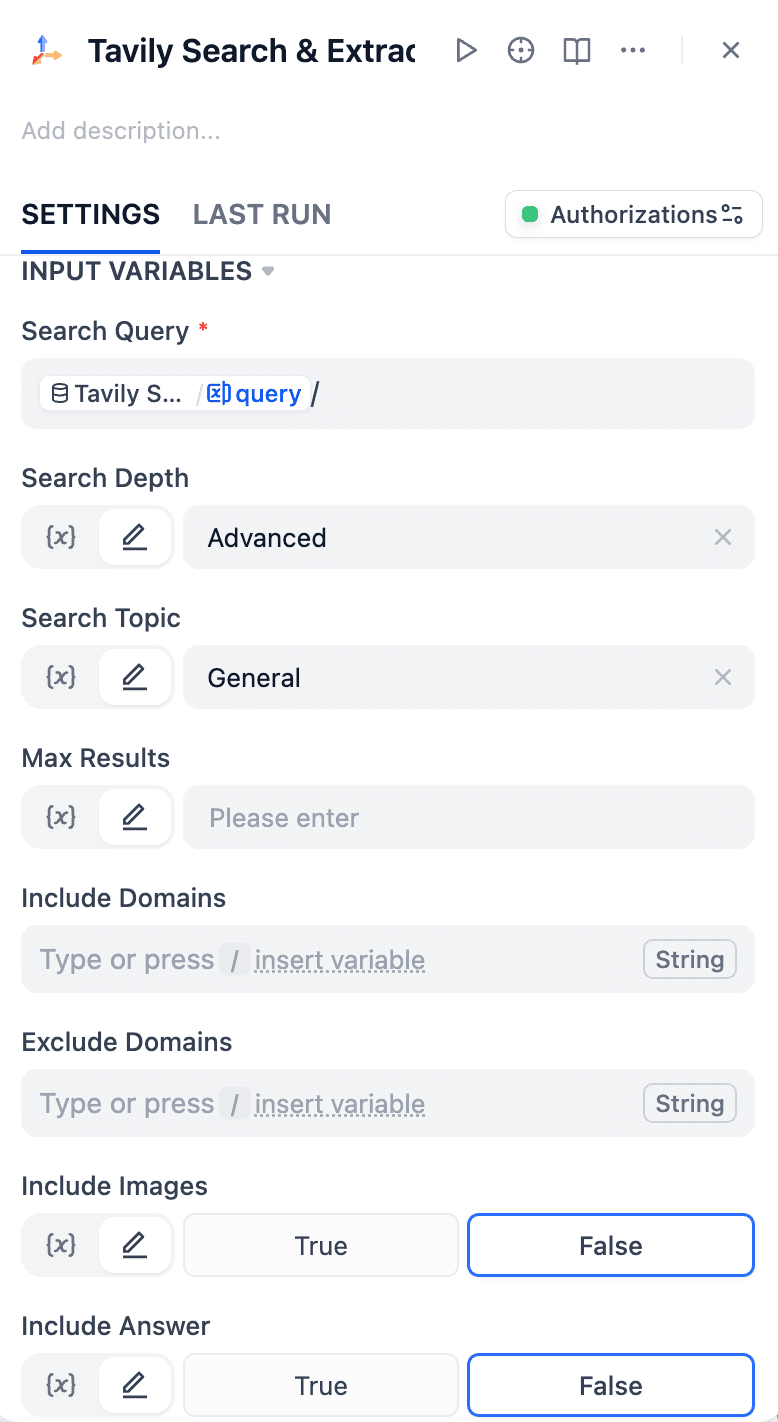
- 配置 LLM 节点,将 Tavily 的输出内容作为系统提示词(System Prompt)的上下文。
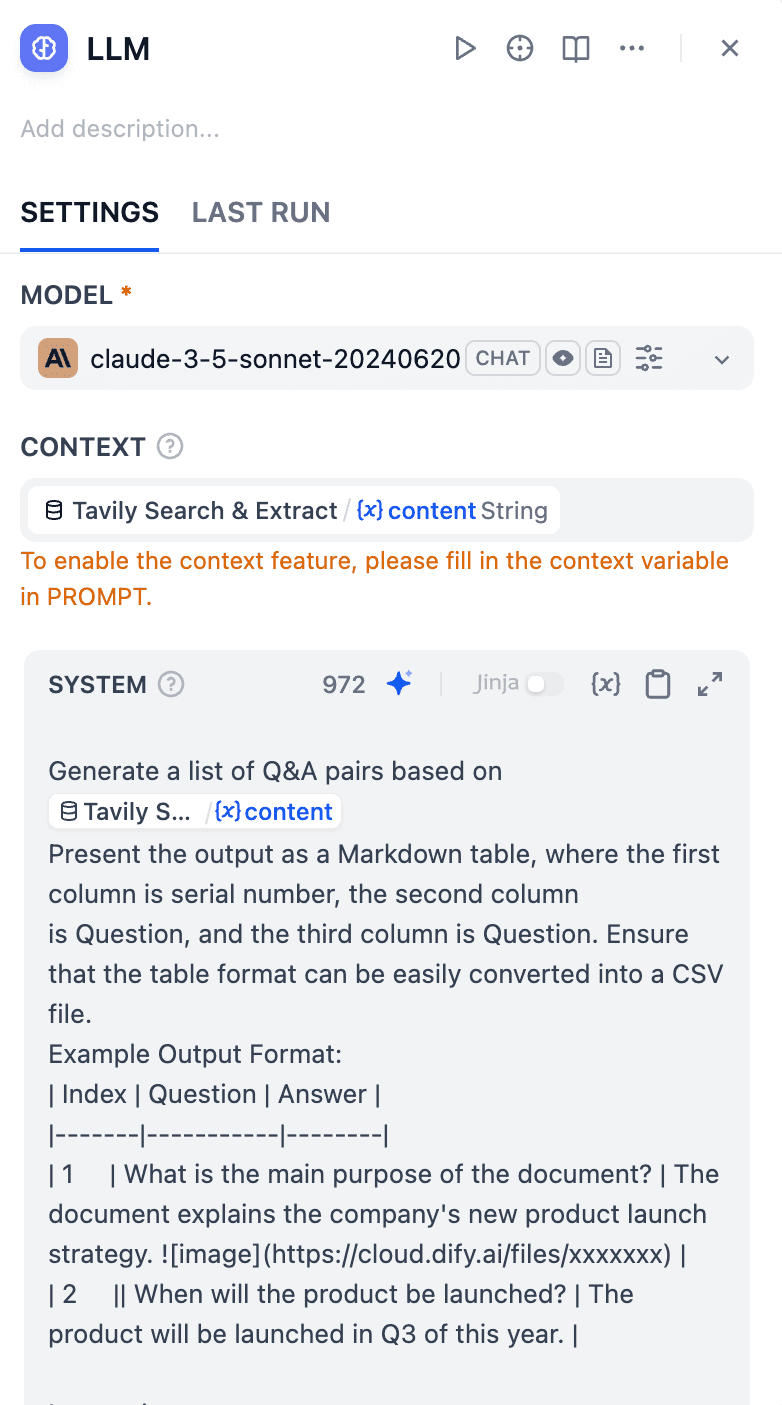
- 最后一步:配置知识库节点。设置索引类型,选择向量化模型,并调整检索参数。发布流水线后,即可正式运行。
实战应用
以实际案例为例:我们抓取了 Tavily 的帮助文档。每篇文档均被处理为问答对,并自动存入知识库。
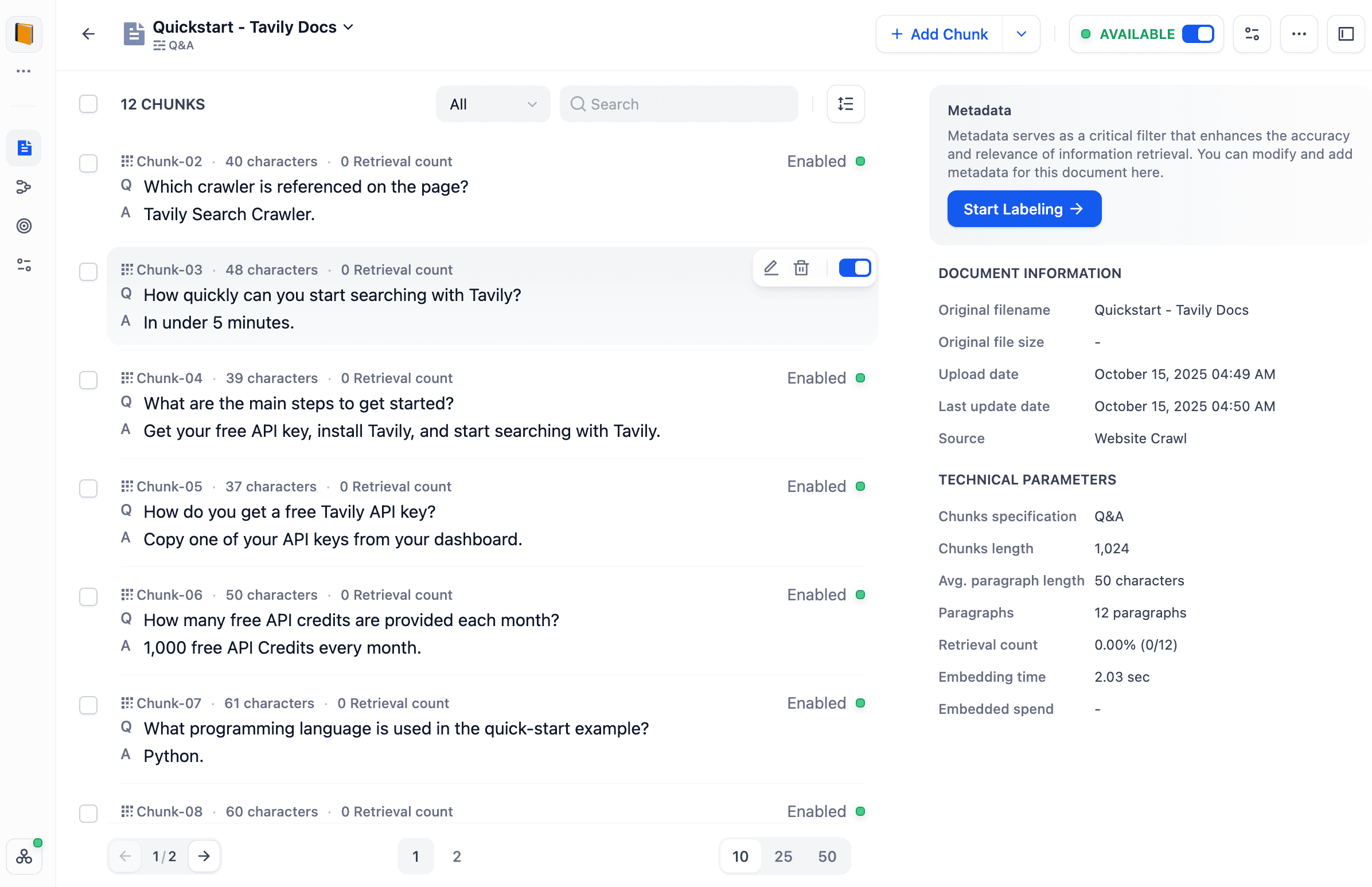
现在,该知识库已全面接入您的所有 Dify 应用。无论是聊天机器人、智能体还是工作流,只要需要上下文增强,均可直接调用。
关于 Tavily
搜索、提取、抓取。专为开发者打造的网络访问技术栈。Tavily 通过实时搜索、结构化数据提取和全页面抓取工具集,为下一代智能体提供核心动力。这些工具覆盖了智能体访问实时网络与进行逻辑推理所需的全部能力。Tavily 专为 RAG、自主决策及生产级智能体系统而设计。
关于 Dify
Dify 是一款开源的 LLM 应用开发平台。其直观的界面整合了智能体工作流、RAG 流水线、智能体能力、模型管理与可观测性等功能。它助您快速完成从原型验证到生产部署的全流程。