分类:Release
知识库现已支持多模态检索
摘要:Dify 知识库 v1.11.0 正式支持多模态检索。通过统一的语义空间,系统可同时理解并检索文本与图片,实现“图搜文”、“文搜图”等能力。结合视觉大模型与 RAG 流程,企业可将产品手册、架构图等视觉资产转化为可计算知识,大幅提升智能问答与自动化工作流的准确性与实用性。
企业知识从来就不局限于文本。产品手册里有实拍照片,技术报告附带架构图,培训指南则满是 UI 截图。这些视觉资产的信息密度和重要性,往往不亚于甚至超过文本本身。
多模态嵌入能力虽已出现一段时间,但鲜有产品能将其真正落地到知识库方案中。过去,企业通常面临两难:要么搭建复杂的跨模态流水线,将图文分开处理后再强行拼接;要么直接忽略图片,只做纯文本检索。这两种做法都存在明显短板。
如今,Dify 知识库正式支持多模态能力。在 Workflow 应用中,文本与图片可被统一理解、检索和调用。AI Agent 获取的上下文不再局限于文字。Agent 现在能够“看懂”图片,解析图中信息,并据此生成精准回答。
核心突破:统一的语义空间
自 Dify v1.11.0 起,我们在统一的语义空间中引入了多模态嵌入技术。通过将图文映射到同一坐标系,系统现已支持“图搜文”、“文搜图”与“图搜图”,搜索准确率得到显著提升。
多模态支持
- 自动提取图片:系统会自动抓取 Markdown 链接引用的图片(支持 JPG、PNG、GIF,单张不超过 2MB)。启用多模态 Embedding 模型后,这些图片将被向量化,并与文本一同存储以供检索。
- 丰富的模型生态:Dify 兼容多家云厂商与开源生态的多模态 Embedding 及 Rerank 模型,涵盖 AWS Bedrock、Google Vertex AI、Jina 和通义千问等。具备多模态能力的模型在设置面板中均带有
VISION标识,方便快速筛选。
从“语义匹配”到“视觉理解”
- 直观捕捉意图:用户既可用自然语言描述需求,也可直接上传相关图片。系统会同步检索语义相关的文本与图片,帮助用户快速定位关键信息。
- 完整的 RAG 推理链路:搭配支持视觉的 LLM 使用时,AI 不再仅依赖文本引用。它可将相关图片纳入推理过程,解析图中细节并给出说明,从而输出更准确、更有用的回答。
技术价值:为何 RAG 需要 Embedding 与 Rerank 协同
在典型的 RAG 架构中,信息需经历“分块(Chunking)- 索引(Indexing)- 检索(Retrieval)- 重排(Reranking)- 生成(Generation)”的流水线。这一过程将零散文档转化为精准的信息流。在此框架下,Embedding 与 Rerank 缺一不可:
- 多模态 Embedding:将内容映射至向量空间,完成第一轮快速相似度匹配。它决定了你的查询能否在海量知识库中精准定位相关内容。
- 多模态 Rerank:评估查询、文本与图片之间的具体相关性。它确保最关键的文图证据被优先提取,为 LLM 提供最精准的上下文。
这些能力的真正价值,在于让图片成为可检索、可排序、可执行决策的证据。在企业的 RAG 与 Agentic Workflow 中,这打破了文档处理的边界。产品规格书、架构图和截图不再是“装饰”,而是可计算的知识资产。
示例场景:基于“看图问答”的助手
用户现可描述问题并上传照片,一键触发“检索 - 识别 - 分析 - 回答”的完整工作流。
步骤 1:创建多模态知识库
-
导入文档:新建知识库,上传你的《产品手册》。
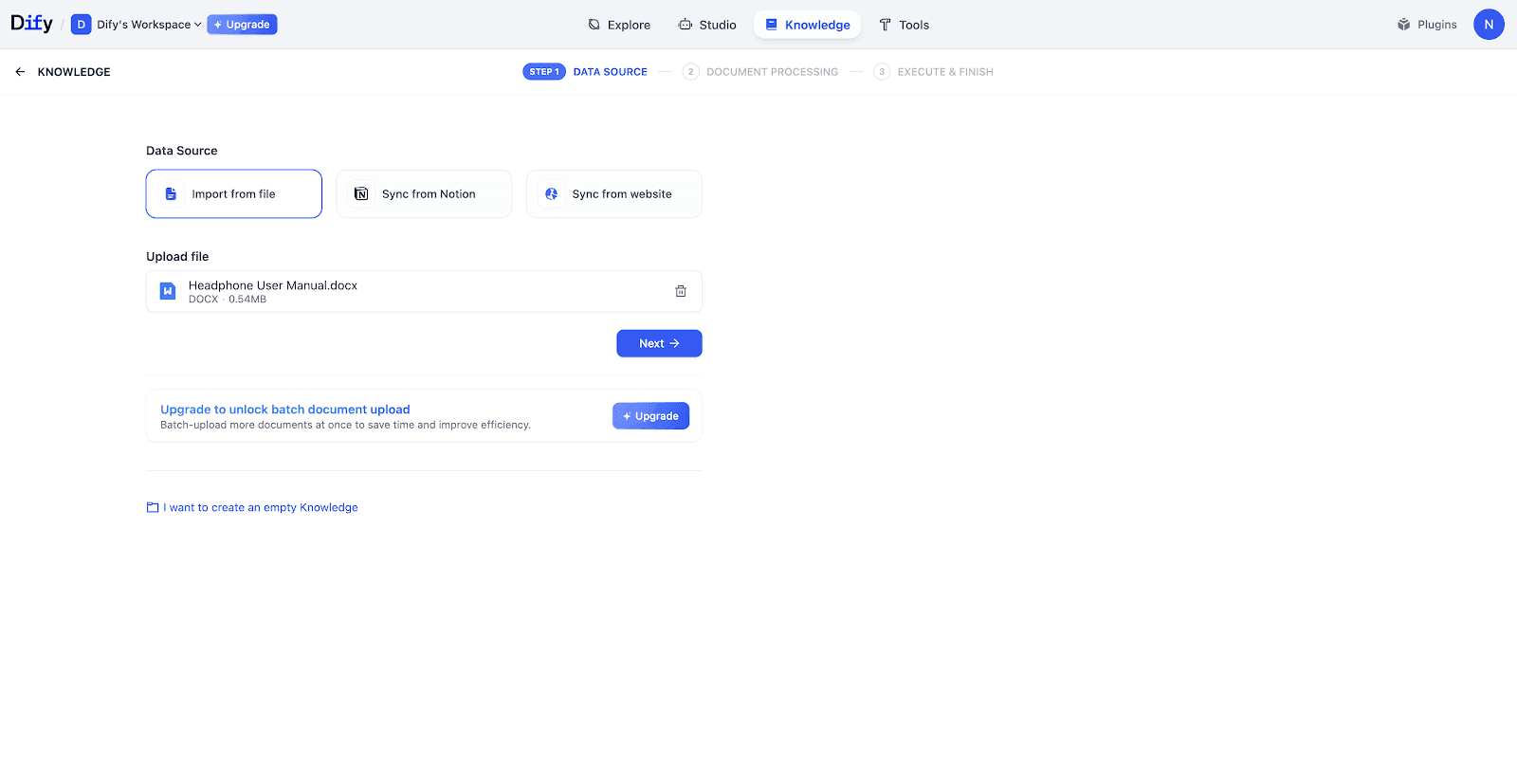
-
模型配置:选择带有
VISION标识的 Embedding 与 Rerank 模型。预览区中的图片会立即进入处理状态。
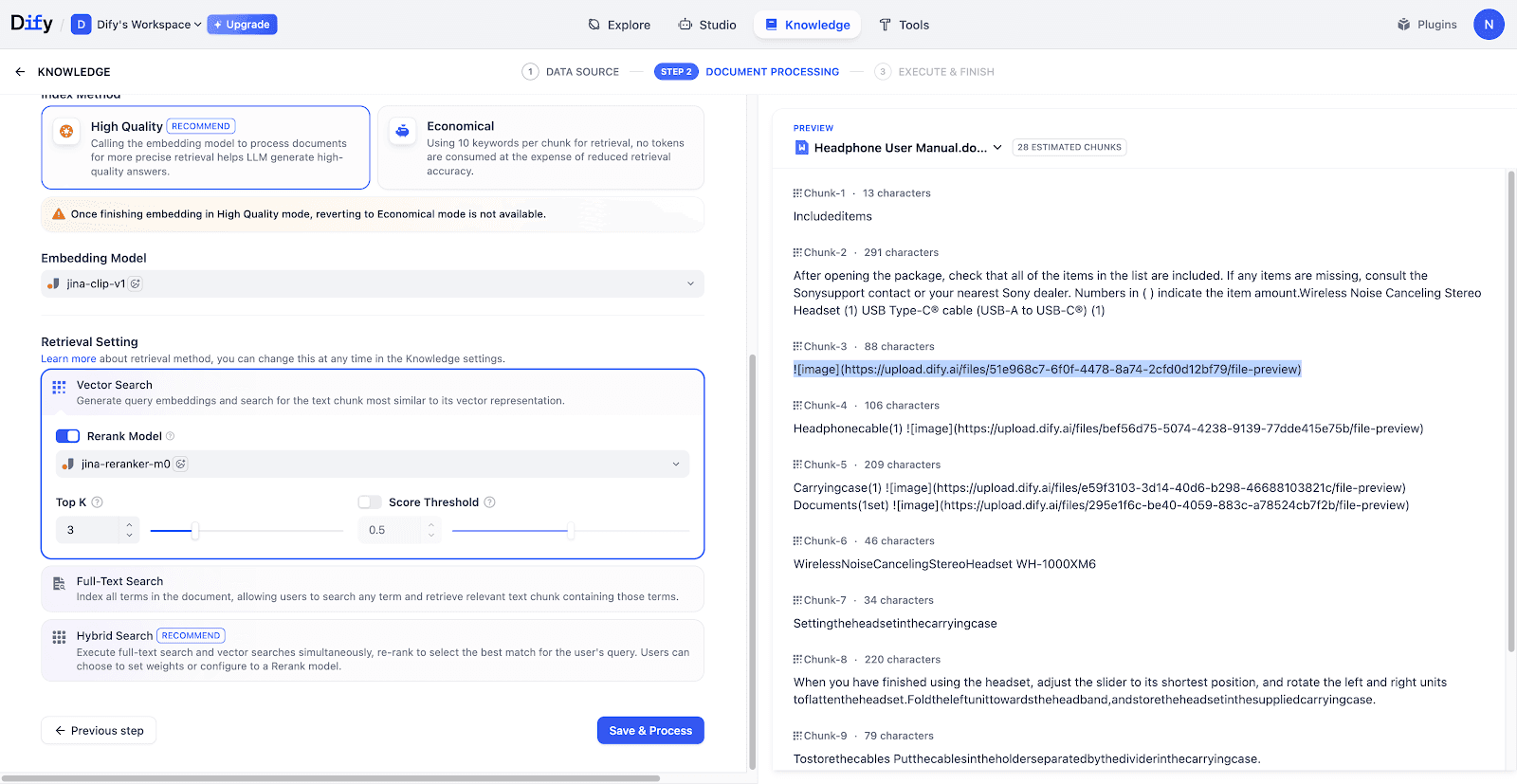
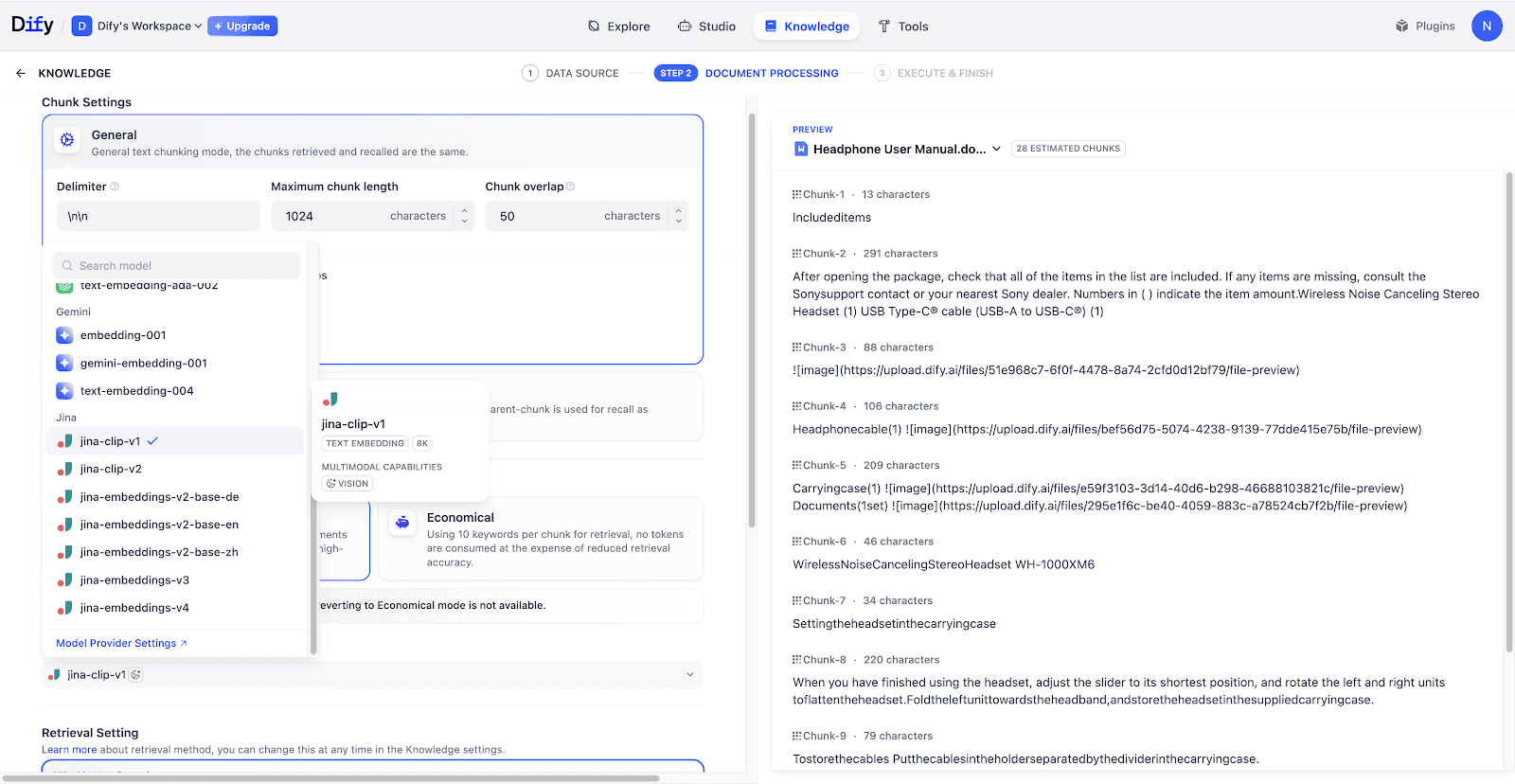
-
图片分块管理:图片支持按 Chunk 级别管理。若使用多模态 Embedding 模型,图片会被向量化并直接参与检索;若使用纯文本模型,则仅在检索到对应 Chunk 时,作为附件返回。
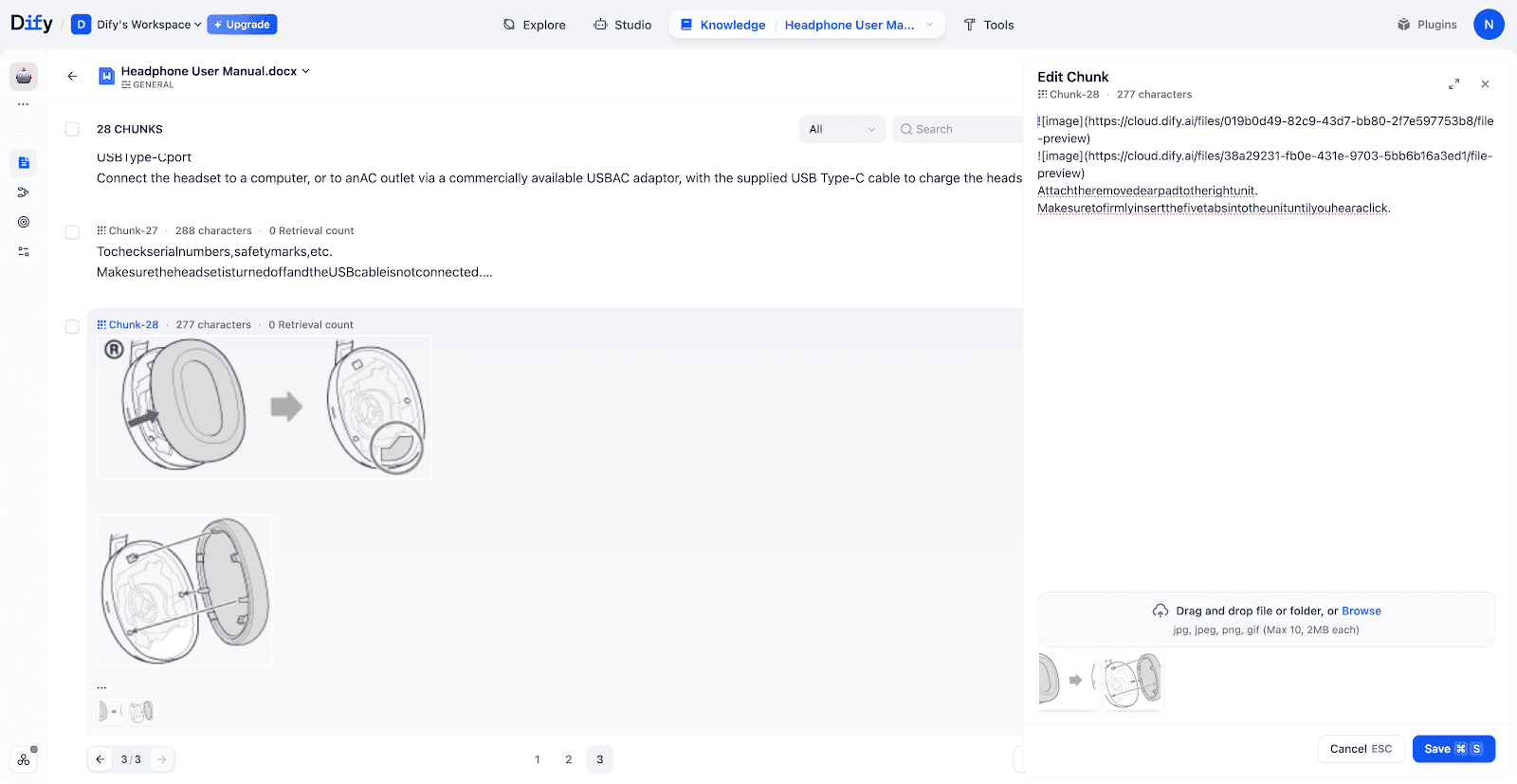
-
检索测试:本次测试中,上传一张耳机照片,系统成功匹配到对应的说明书章节,包含结构图与配件清单。
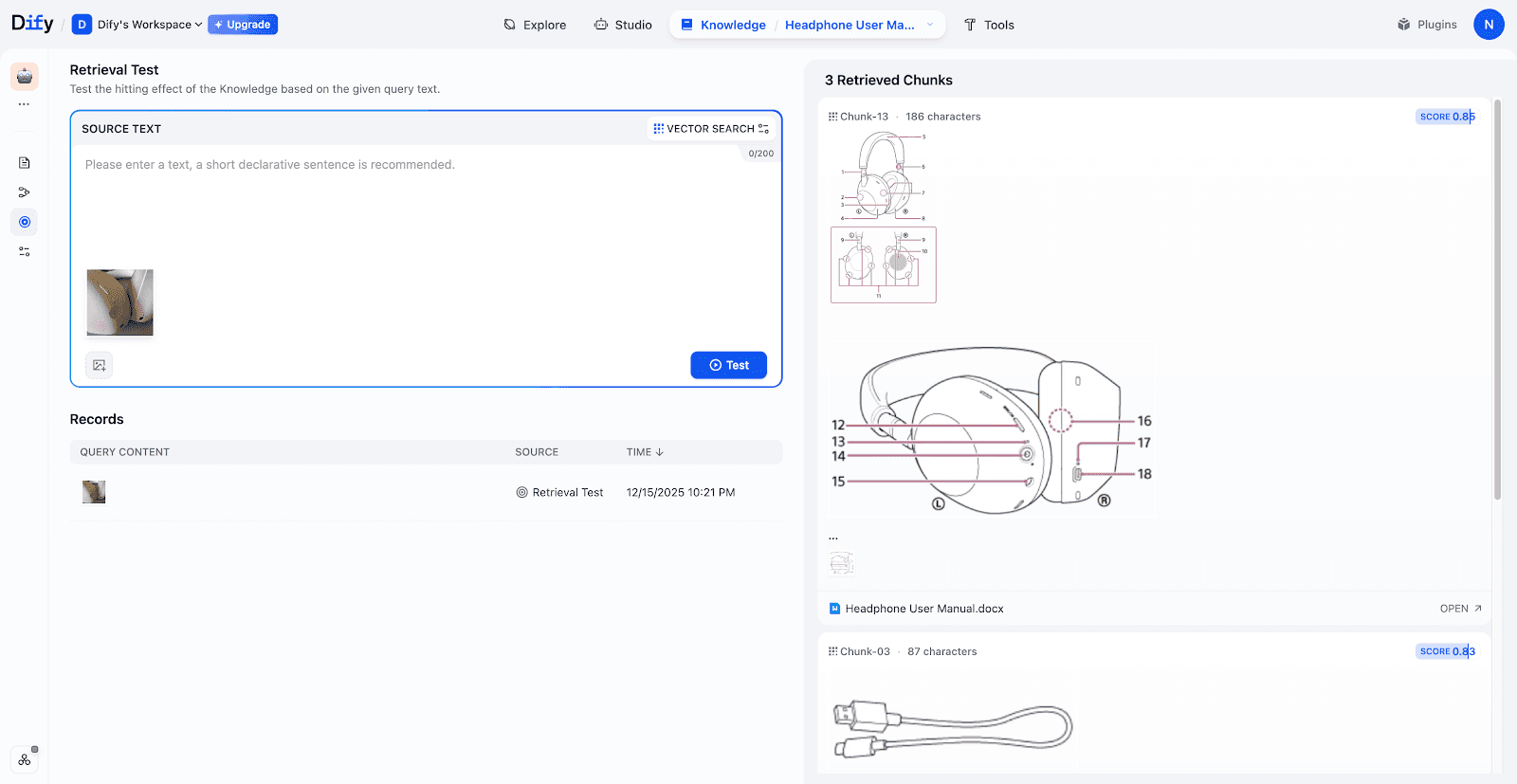
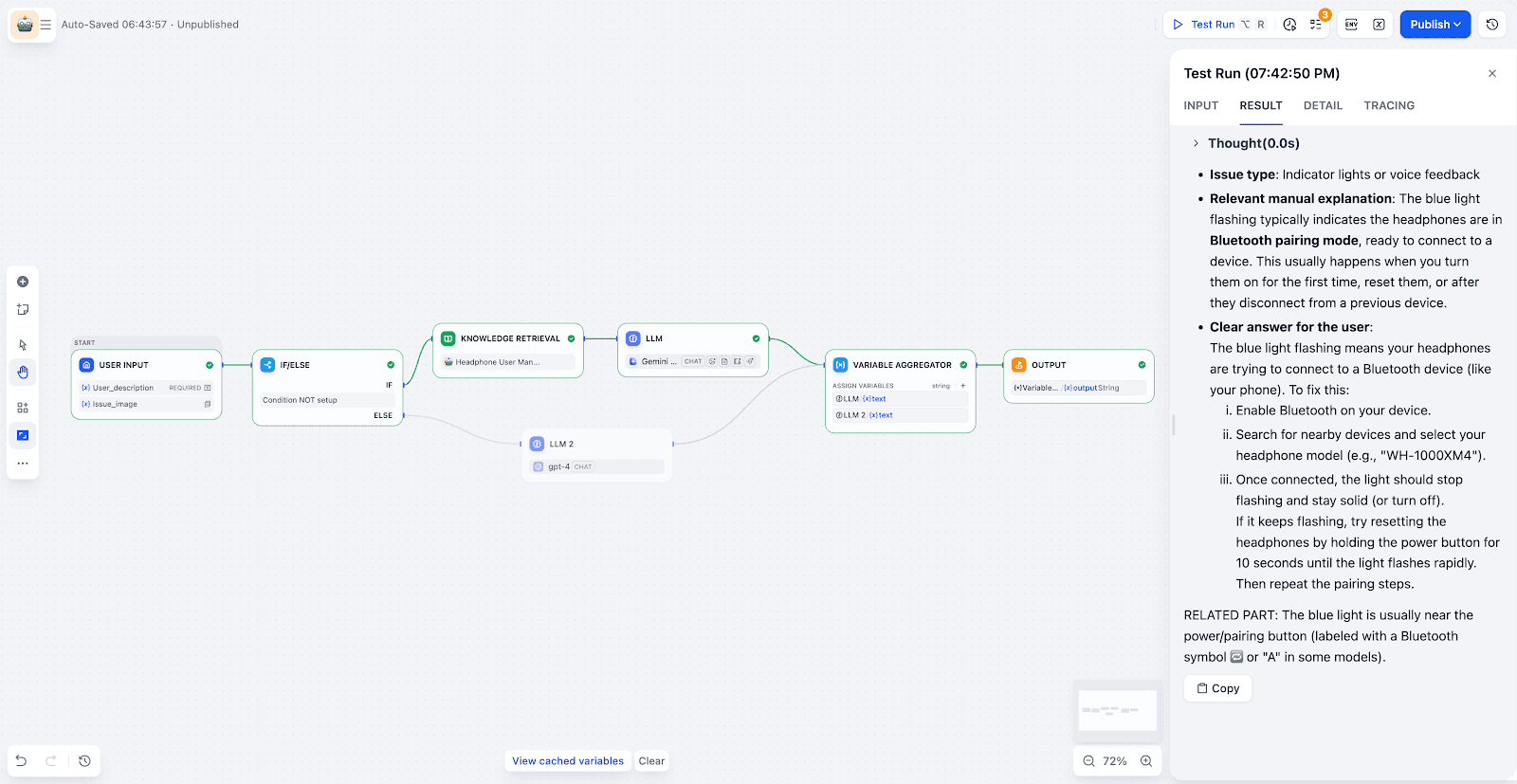
步骤 2:搭建自动化查询 Workflow
-
输入与路由:Workflow 接收用户提问与图片。通过
IF/ELSE节点判断,若知识库可解答则继续处理,否则转交其他渠道(如人工工单)。
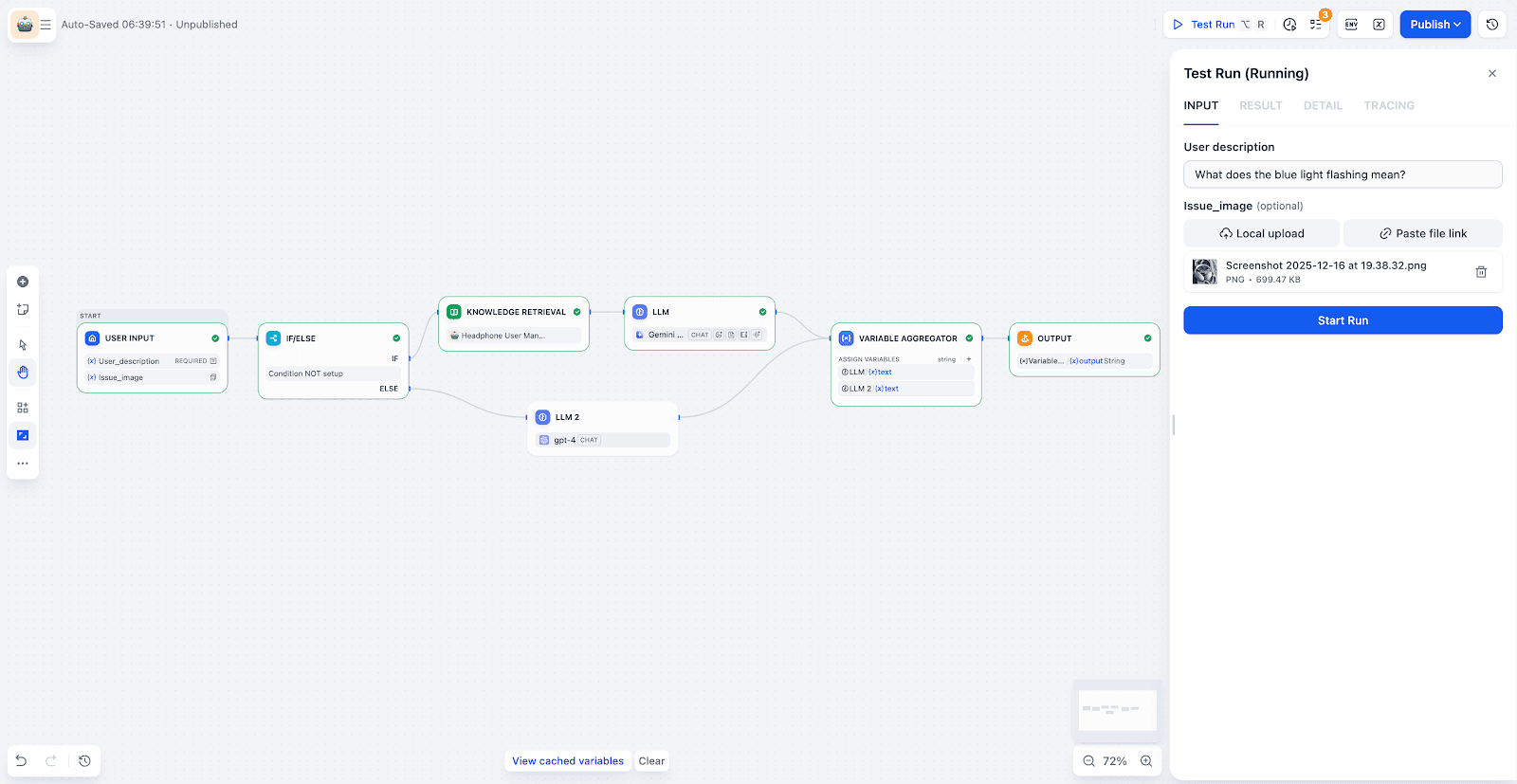
-
知识检索:系统自动检索知识库,提取最相关的文本与图片 Chunk。
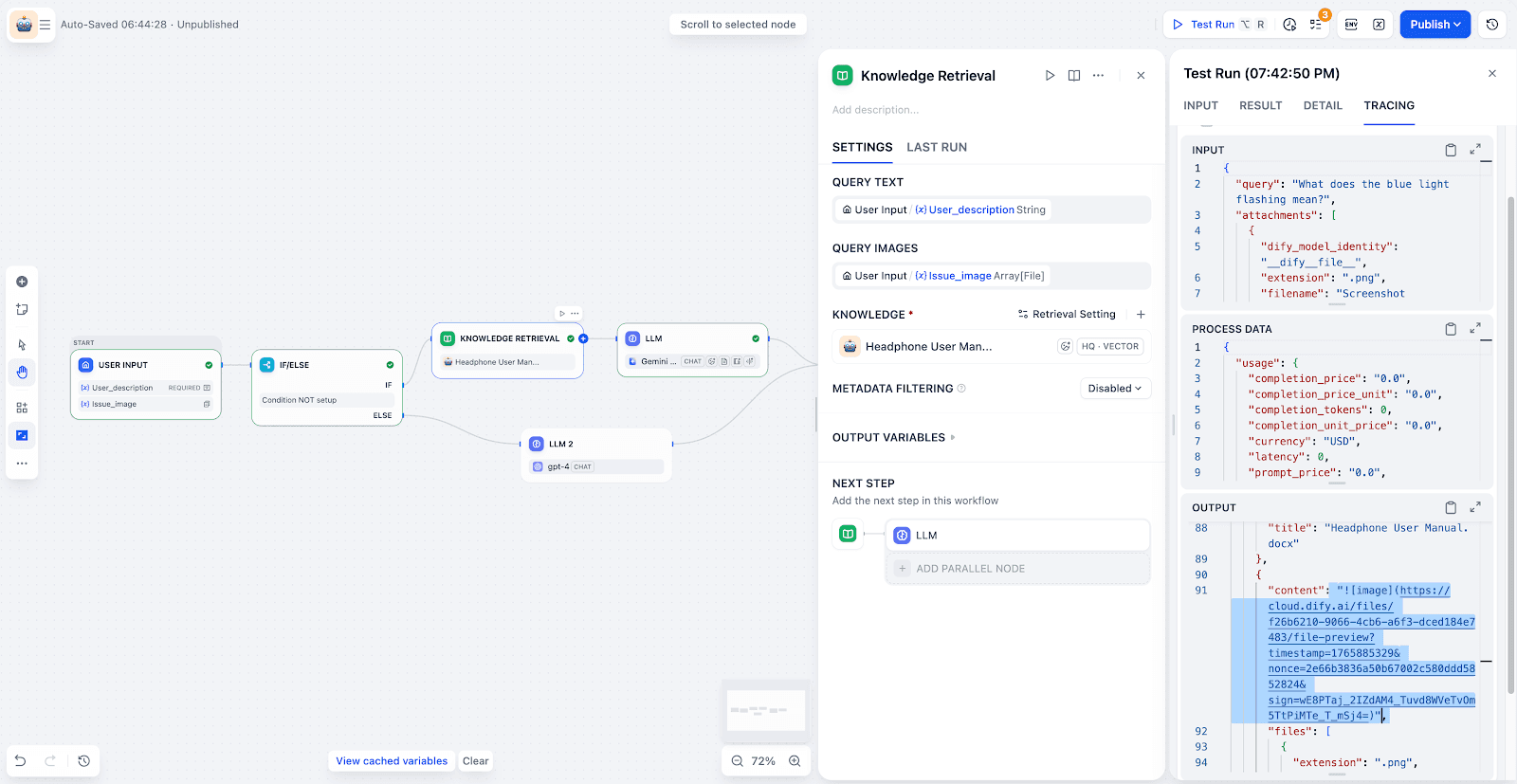
-
视觉 LLM 节点:开启 Vision 模式并绑定上传的图片变量。LLM 可直接提取图中关键信息,结合任务需求进行分析与问题定位。
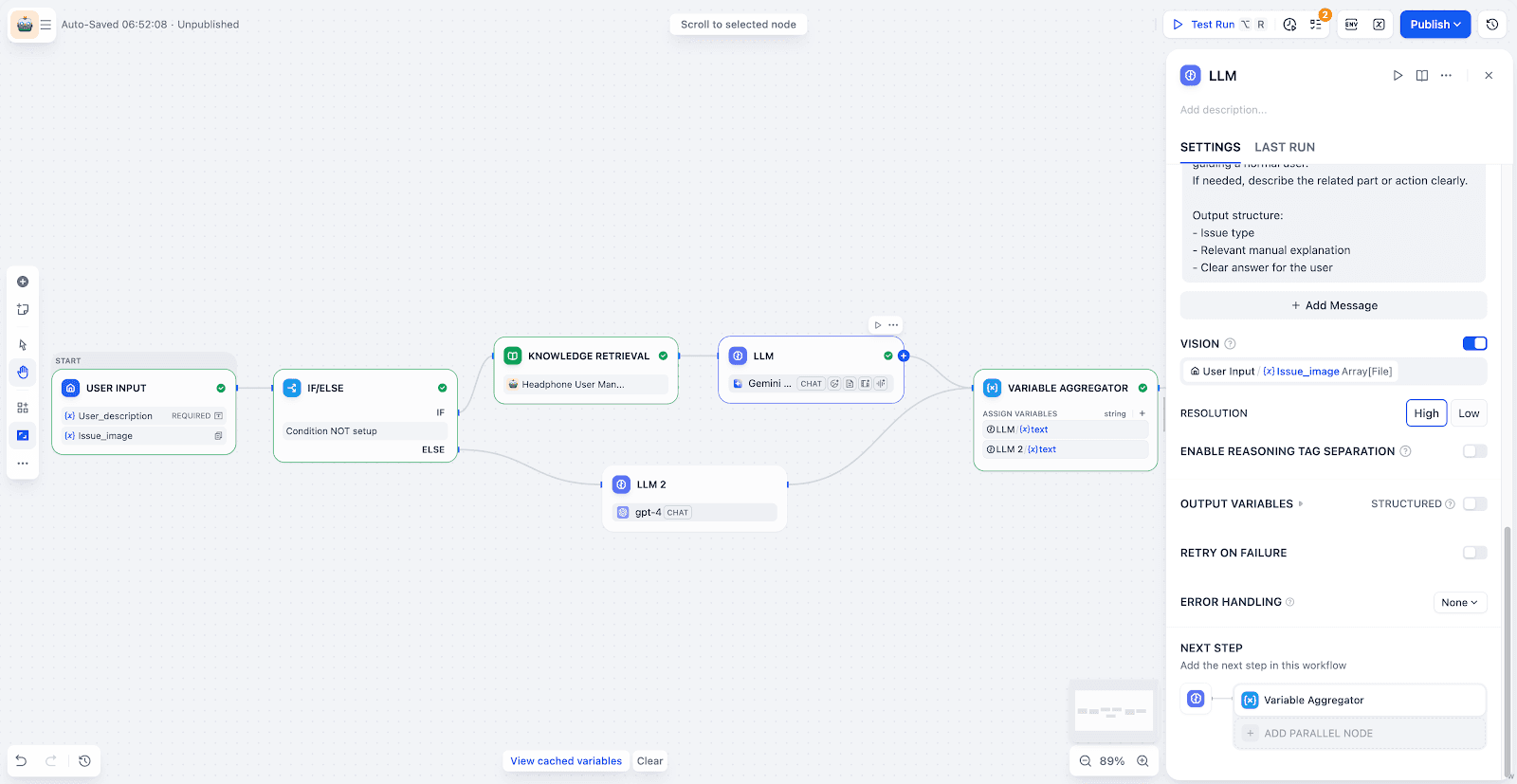
-
结果聚合与输出:最后使用变量聚合节点,合并检索结果与 LLM 分析内容,输出清晰、可执行的回答。
结语:从文本检索到智能执行
多模态知识库的上线,标志着 Dify 从单一的文本检索工具,全面进化为企业级知识与自动化平台。
这不仅仅是“读懂”一张图片。更是将视觉信息转化为 Workflow 上下文。该上下文可直接支撑推理与动作执行。无论是查询技术文档、发送自动化通知,还是驱动复杂业务流程,你的 Agent 都能从被动问答,迈向真正的决策与执行。
最终,它将蜕变为一个务实、可靠,且真正适用于企业级生产的系统。